

このPDFや画像の文字、コピーできたら効率的なのになぁ
とコピーできないことに不便さを感じたことがあると思います。
そんな方に向けて、PDFや画像内の文字をOCR(光学文字認識)技術を使って、文字列として扱えるように変換する方法(ソフトウェア)を紹介します。

目次
OCR(光学文字認識)技術とは?
OCR(Optical Character Recognition)とは、スキャナで読み込まれた文字、画像内の文字などテキスト情報ではなく、画像情報としての文字を読み取り、デジタルの文字コード(※)に変換する技術のことです。
※テキストエディタやWordで扱えるような普通の文字列のこと
普段のパソコン作業の中で、
このPDFや画像の文字、コピーできたら効率的なのになぁ
と不便に思ったことは、一度はあると思います。
このOCR技術を使うことで、そういった画像内の文字情報を扱いやすいデジタルの文字コードに変換することができます。
主に、次のような場合に役立ちますね。
- jpg, pngなどの画像ファイル内の文字
- PDFファイル
- 文字を選択できないWebページ(稀にある)
このような普通の文字として扱えないものを文字コードに変換したい時に、OCRは役立ちます。
使いどころとしては、自分が作成している資料に、
- 引用したり
- 文言を少し変えて使ったり
という場合が多いと思います。
しかし、いざその文章を使いたいとなっても、カーソルを合わせて選択できなければ、コピーもできないため、文字コードの文字列として扱うことができません。
そういう場合に、OCR技術を活用して、文字コードの文字列に変換するという訳ですね。
1,2行だけであれば、自分で文字入力した方が速いです。
しかし、数十行あるような長文であれば、さすがに自分で入力していくのは、時間がかかりますし、何よりもかなり疲れます。
 ケンさん
ケンさん
そこで、OCR技術を使って、PDFや画像の文字をデジタルの文字コードに変換できるソフトを紹介します。
OCRが使えるソフト『PDFelement』

OCR技術を使って、PDFや画像を変換できるソフトウェアは色々ありますが、おすすめとしては、『PDFelement
PDFelementとはどういうものか簡単に解説すると、PDFファイルの編集や使い勝手の良いWord、ExcelやPowerPointなどに変換できるソフトウェアです。
また逆に、Word、ExcelやPowerPointや画像などをPDFに変換することもできますし、一括で複数のファイルの変換も可能で、PDFに関する作業をオールインワンでできます。
PDFelementの概要について、こちらの記事で詳しくレビューしているので、参考にしてみて下さい。
≫ 関連記事:Wordなどの変換も可能なPDF編集ソフト『PDFelement』を徹底レビュー!PDF編集をオールインワンで効率化!
PDFelementのOCR機能について
さて、本題のOCRについてですが、このPDFelementの一機能として、PDFや画像ファイルをデジタルの文字コードに変換する機能が備わっています。
PDFや文字の含まれた画像(※)をPDFelementのOCR機能にかけると文字として扱うことができます。
※画像ファイルの場合は、一度PDFファイルに変換されるようです。
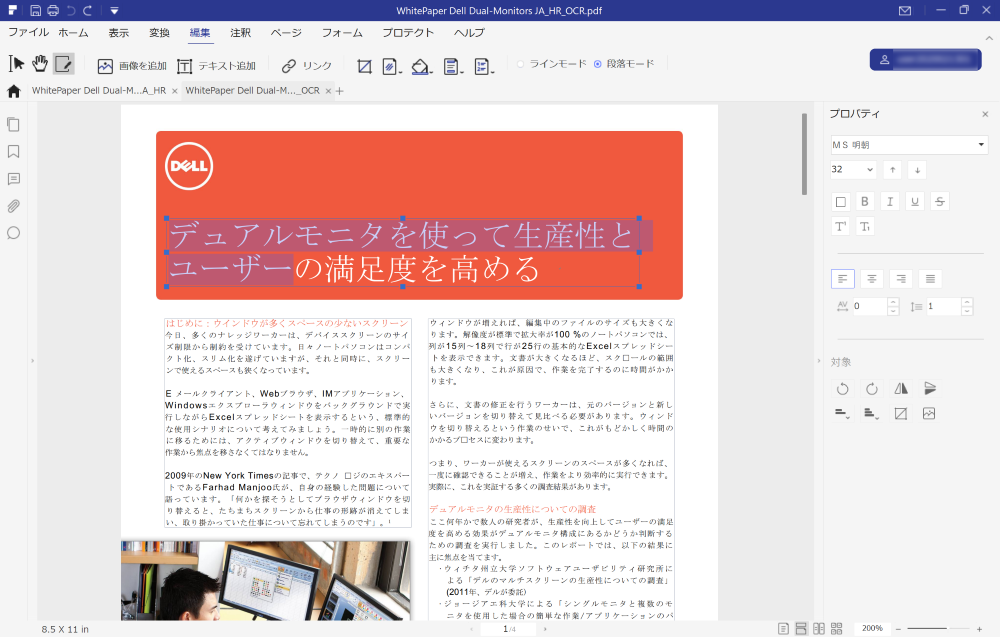
実際に変換してみると、タイトル部分の青くなっている部分のように、文字列を選択することができます。
このままコピーすることができるので、文字列として自由に扱うことができるようになります。
手順も非常に簡単でして、
- PDFや画像ファイルを開く。
- メニューから[変換] -> [OCR]と進む。
- 変換が終わるまで待つ(4ページで15秒ほど)
- コピーしたい文字列を選択して、コピーする
メニュー画面

これだけで、上の画像のように、PDFファイル内の文字を選択できるようになります。
PDFelementの機能制限について
PDFelement
OCRを使った変換は無料版でもできますが、変換後の文字のコピーに関しては無料版ではできない仕様になっています。
そのため、PDFelementの使い勝手やOCRの認識の精度の高さを無料版で確認して、十分やりたいことができると思ったら、有料版を購入して、コピーもできるようにするという形になりますね。
PDFelementによるOCRの認識精度の検証
OCRによる文字列の認識には精度があります。
精度が悪ければ、誤変換が多くなり使い物になりません。
間違っている箇所があれば、原本を見て1文字1文字修正という形になり、使い勝手が非常に悪くなってしまいます。
1文字1文字修正するというのは意外と面倒で、個人的には文章を入力するより辛いですね。
そこで、PDFelementのOCR機能の精度を検証したいと思います。
上の画像の通り、一見するとおかしいところは無く、ほとんど期待通りに変換できていると思います。
しかし、より具体的な精度を知りたいので、総文字数と誤変換の文字数から精度を割り出すことにします。
検証に使うPDFファイルは、Dellが発表しているデュアルモニタの生産性とユーザーの満足度に関する資料を使いたいと思います。
このPDFファイルは、計4ページで、3411文字あります。
※図のタイトルの文字と言った細かい部分は省き、本文のみの文字数です。
OCRによる変換後のテキストを1文字ずつ確認したところ誤変換は、8箇所でした。
まとめると次のようになります。
PDFページ数:4ページ
検証文字数 :3411文字
誤変換数 :8箇所
正解率 :99.76%
8箇所間違いはありますが 3411文字中の8箇所ということで、正解率が99%以上と非常に高く、全然許容できるレベルだと思います。
これだけであれば、1文字ずつ修正しても大して苦にはなりませんね。
むしろ、3411文字も一から入力せずに済むので、大幅な効率アップに繋がるはずです。
では、8箇所の間違った部分を見ていきましょう。
ウィンドウの「ィ」が「イ」に変換される


(左:PDFファイル、右:テキスト変換後)
ウィンドウの「ィ」が小文字の「イ」になっていますね。
この箇所の他に、同様の誤変換が4箇所ありました。
とは言え、ウィンドウという単語を全部間違えているというわけでは無く、全11箇所中、4箇所の誤変換でした。
7箇所は正確に変換されているということですね。
ウィチタ州立大学の「ウ」が小文字の「ゥ」に変換される


(左:PDFファイル、右:テキスト変換後)
ウィチタ州立大学の「ウ」が小文字の「ゥ」になっていますね。
この箇所の他に、もう1箇所同様の誤変換がありました。
しかし、「ウィチタ」という単語は全部で4箇所あり、正解2箇所、誤変換2箇所だったので、必ずしも「ウ」が小文字に誤変換されるということは無いようですね。
また、他にも「ウィンドウ」「ウィンドウ」「ブラウザ」というように、「ウ」の入っている単語はたくさんありますが、他は正しく変換されていました。
デュアルモニタの「ニ」、テクニカルの「ニ」が「ユ」に変換される


(左:PDFファイル、右:テキスト変換後)


(左:PDFファイル、右:テキスト変換後)
「ニ」が「ユ」になっていますね。
「ディアルモニタ」「メニュー」と言った「ニ」は正しく変換されていたので、こちらも場合によっては、低い確率で誤変換されてしまうようですね。
「ニ」と「ユ」では、縦棒に1本入っているか、入っていないかの違いなので、プログラムからすれば似ていると判断されてしまい誤変換という感じになるのでしょうか。
誤変換についてまとめると次のようになりますね。
【誤変換についてのまとめ】
1.「イ」「ィ」、「ウ」「ゥ」と言った大文字、小文字
2.「ニ」と「ユ」のように似た文字
で誤変換が起きる可能性がある。
とは言え、全ての文字でそうはならず、発生しても低確率
という結果ですね。
とは言え、正解率は99%以上なので、この程度であれば手作業で直しても、トータルで効率的であることは変わらないでしょう。
OCR変換後の文字コードの文字列に半角スペースが入る
あと少しだけ気になったのが、変換された文字コードは、PDFの改行のポイントで半角スペースが入っているということですね。


(左:PDFファイル、右:テキスト変換後)
例えば、上のPDFファイルのように文章の途中で改行が来ている場合、変換後のテキストを見ると半角スペースが入っていることが分かります。
この部分については、テキストエディタなどの「置換」機能を使って、一括で半角スペースを削除するというような方法が必要そうですね。
まとめ:手っ取り早くPDFや画像をテキスト化したいのであれば『PDFelement』
OCR(光学文字認識)技術とPDFや画像ファイル内の文字を文字コードの文字列に変換する方法を解説しました。
資料などを作成している際に、
このPDFや画像の文字、コピーできたら効率的なのになぁ
と一度でも感じたことのある方は、ぜひ試してほしいですね。
PDFelementを使えば簡単な手順で変換することができ、さらに変換の精度も99%以上と高いので、おすすめですね。
無料版では、変換した文字列のコピーはできませんが、OCR変換はできるので精度のチェックや使い勝手もわかるので、気になる方は、ぜひ無料版から使ってみて欲しいですね。










